解鎖數據新價值 基于區塊鏈的DataVLT大數據分析服務深度解析
在數據爆炸式增長和數字化轉型浪潮的驅動下,大數據分析已成為企業決策與創新的核心引擎。數據孤島、隱私泄露、信任缺失與價值分配不均等問題始終是行業痛點。DataVLT大數據分析服務應運而生,它創新性地將區塊鏈技術的核心優勢融入大數據分析的全生命周期,旨在構建一個安全、可信、高效且公平的數據價值生態。
一、 核心理念:區塊鏈賦能大數據
DataVLT的核心理念在于利用區塊鏈的分布式賬本、智能合約、加密算法與通證經濟模型,重塑傳統大數據服務的信任基礎與協作模式。
- 數據主權與隱私保護:通過非對稱加密和零知識證明等技術,DataVLT確保數據提供方在共享數據進行分析時,始終擁有數據所有權和控制權。原始數據無需離開本地,僅通過授權方式提供計算所需的最小信息單元,從根本上杜絕隱私泄露風險。
- 不可篡改與全程可溯:所有數據的使用授權、分析過程、模型調用和結果生成記錄都將上鏈存證。這為數據來源的可靠性、分析過程的合規性以及最終結果的審計追蹤提供了不可篡改的證據鏈,極大增強了分析結果的可信度。
- 智能合約驅動的自動化協作:數據分析任務的需求方、數據提供方、算力提供方和算法模型開發者之間的協作規則(如定價、授權條件、收益分成等)均由智能合約預先定義并自動執行。這消除了中間環節,降低了信任成本,實現了價值的精準、即時分配。
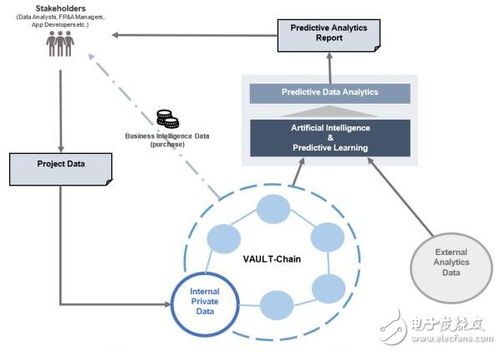
二、 服務架構與核心功能
DataVLT構建了一個分層、模塊化的服務體系:
- 數據層:對接各類結構化與非結構化數據源。通過區塊鏈身份認證和加密網關,實現數據的安全接入與標準化描述。數據目錄與元數據上鏈,便于發現與確權。
- 計算與模型層:整合分布式計算框架(如Spark, Flink)和AI/ML模型庫。智能合約負責調度任務,在獲得授權的前提下,將計算任務派發至可信執行環境(TEE)或聯邦學習節點中進行安全計算,確保原始數據“可用不可見”。
- 區塊鏈核心層:作為整個系統的信任基石,負責維護身份體系、記錄所有操作日志、執行智能合約并管理系統內的通證流轉。通常采用高性能聯盟鏈或結合Layer2擴容方案,以平衡效率與去中心化程度。
- 應用與價值層:向終端用戶提供易用的數據分析平臺、API接口及可視化工具。通過原生通證經濟體系,激勵生態內各方參與者貢獻數據、算力與算法,并按其貢獻公平地獲取收益,形成可持續發展的數據市場。
三、 典型應用場景
- 跨機構聯合風控:多家金融機構可在DataVLT平臺上,在不暴露各自客戶原始數據的前提下,聯合訓練更精準的反欺詐或信用評估模型,共享模型價值。
- 醫療研究協作:不同醫院的研究機構可以安全地共享脫敏后的醫療數據,共同進行疾病趨勢分析或藥物療效研究,同時嚴格保護患者隱私并明確貢獻度。
- 供應鏈透明化:將供應鏈各環節的物流、資金流、信息流數據上鏈并進行分析,企業可以實時洞察供應鏈狀態、預測風險、優化效率,并向上游下游提供可信的數據證明。
- 數字廣告與營銷:用戶可自主授權個人偏好數據(經匿名化處理)用于廣告效果分析,并直接從廣告主的投放預算中獲得數據使用收益,改變傳統模式下用戶數據被無償利用的局面。
四、 優勢與未來展望
DataVLT大數據分析服務的核心優勢在于構建信任、保障安全、激活價值。它不僅僅是技術的疊加,更是一種生產關系的革新,使得數據從被保護的資產轉變為可安全流通、創造共贏的生產要素。
隨著區塊鏈技術的成熟、跨鏈互操作性的提升以及相關法規的完善,DataVLT這類服務有望成為下一代數據基礎設施的關鍵組成部分。它將推動形成一個全球性的、開放而有序的數據要素市場,真正釋放數據的巨大潛能,為各行各業帶來更深層次的數字化轉型與智能化升級。
如若轉載,請注明出處:http://www.yaoseng.cn/product/53.html
更新時間:2026-03-13 17:58:08